




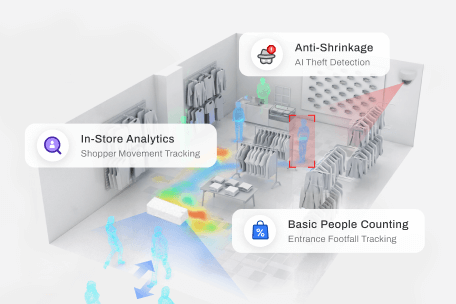
Small Retailer











Understand Behaviour
VLM moves analytics beyond position and duration, interpreting what people are doing within a defined retail context.
Traditional analytics can identify presence, dwell time, paths, and proximity. VLM adds behavioural understanding. It interprets actions such as browsing, product handling, staff interaction, service completion, or irrelevant presence, allowing the same movement data to become more meaningful and more measurable.
Counts to Context
FootfallCam combines people tracking, zone activity, demographic attributes, group behaviour, store layout, and contextual data such as promotions or operating conditions. VLM uses this structured context to classify events into defined categories, creating richer metrics for product engagement, service interaction, and operational activity.
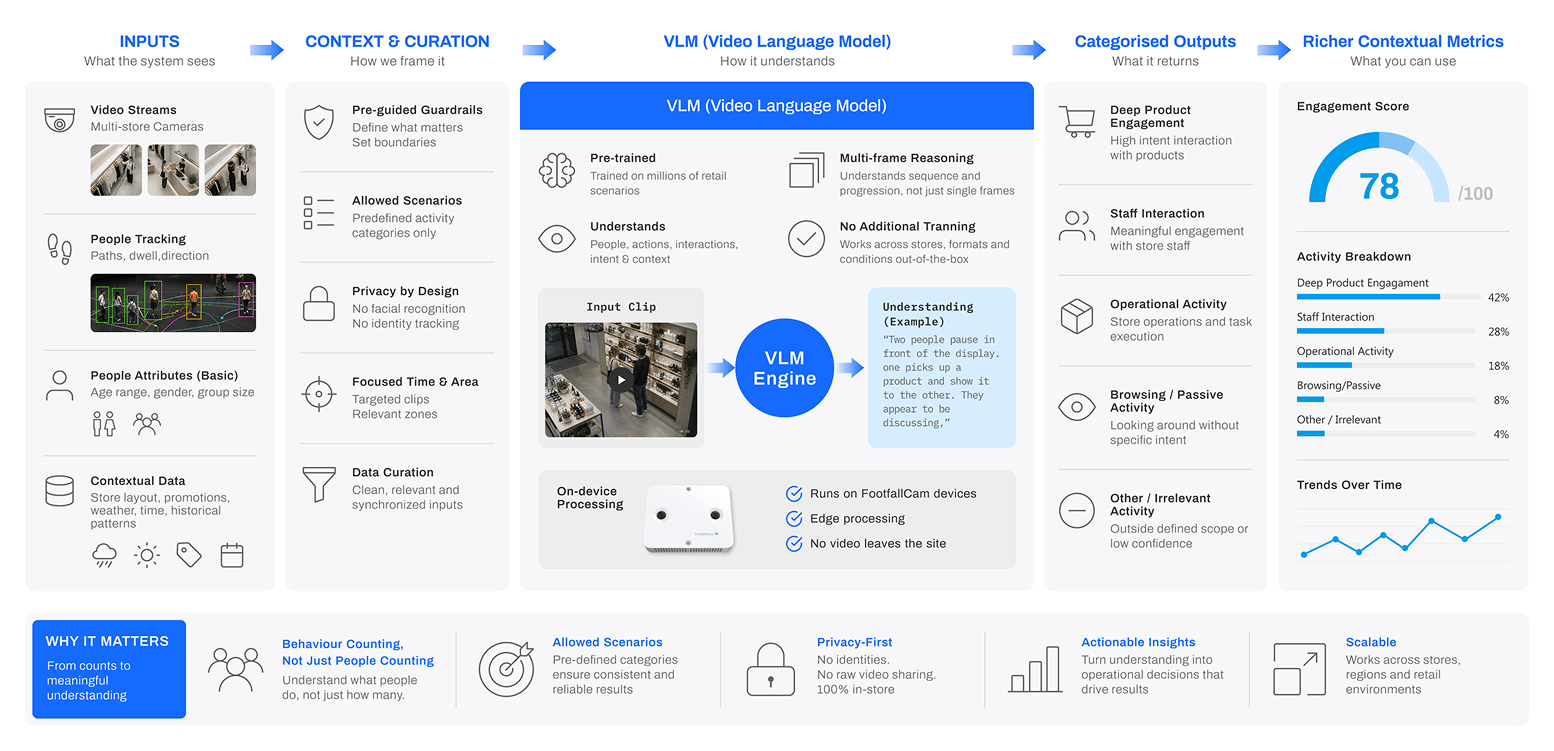
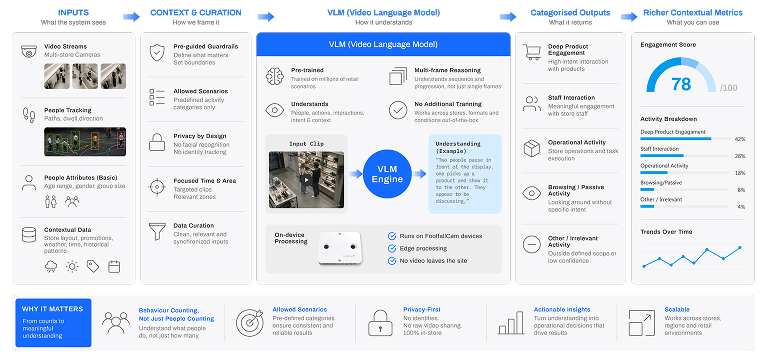
How It Works
Relevant moments are selected, interpreted, classified, and converted into structured retail metrics. VLM is applied within defined business contexts. The system focuses on relevant zones, time periods, and event types, then interprets the selected video moment using pre-set questions and classification rules. The output is not an open-ended description. It is a controlled result mapped to predefined business categories.
Step 1
Detect the Moment
Tracking identifies a relevant event, such as shelf dwell, staff proximity, or service activity.
Step 2
Add Context
Store layout, zone type, group behaviour, time, promotion, and movement history provide the operating context.
Step 3
Interpret Behaviour
VLM reviews the video moment and determines what behaviour is occurring.
Step 4
Classify the Result
The outcome is converted into structured categories such as product engagement, staff interaction, operational task, or irrelevant activity.
Why VLM Works
VLM is pre-trained to understand a wide range of visual situations. This allows FootfallCam to apply video understanding across different retail behaviours without training a separate model for every scenario. The system can interpret multi-frame context, understand interaction patterns, and return focused outputs based on predefined questions.
Contextual Metrics
VLM turns observed behaviour into measurable categories that reflect actual retail activity. A person standing in front of a shelf is no longer measured only as dwell time. VLM can classify whether the person is glancing, browsing, actively evaluating a product, interacting with staff, or not engaged. These classifications become structured metrics that can be reviewed, aggregated, and compared across stores.
Product Engagement
Classifies customer attention from brief interest to active product evaluation, helping retailers understand which displays create meaningful engagement.
Staff Interaction
Identifies service moments such as greeting, assistance, consultation, upselling, or handover, supporting more consistent measurement of service quality.
Operational Activity
Recognises defined staff activities such as restocking, moving boxes, cleaning, or task completion, helping teams measure operational adherence.
Same Moment, Different Meaning
The same location and dwell time can represent very different behaviours. VLM helps distinguish them.A customer may stand in the same area for the same duration, but the behaviour may be entirely different. They may be distracted by a phone, briefly looking, actively browsing, handling a product, speaking casually, or discussing the product with another person. VLM helps separate these outcomes.
Phone Distraction

VLM Output: Person stationary, attention directed to mobile device. No product interaction.
Not Engaged
Casual Glance

VLM Output: Brief visual attention towards products, no hand interaction
Lvl1:Light engagement
Active Browsing

VLM Output: Sustained visual focus on products with exploratory behaviour.
Lvl2: Browsing
Deep Product Interaction

VLM Output: Direct product handling and evaluation behaviour.
Lvl3: High Engagement
Talking to Friend

VLM Output: Conversation detected, not related to product interaction
Not Engaged
Talking About Product

VLM Output: Shared attention towards product with discussion behaviour.
Lvl4: Staff Engagement
AI-generated illustrations only; no real customer data, surveillance footage, or personal information is used or captured.
Verifiable Results
Each classified event can be reviewed, explained, and aligned with the retailer’s operational definition. VLM does not only return a label. It can provide a concise explanation of what was observed, such as product handling, shared attention, staff assistance, or irrelevant presence. This allows teams to review selected events, validate outcomes, and refine definitions over time.
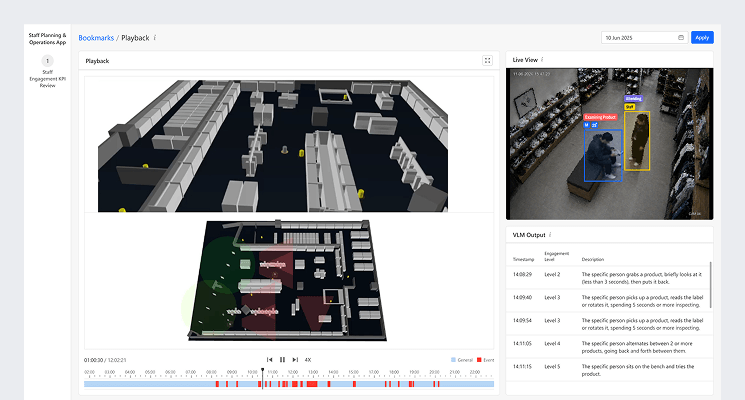
Evidence Review
Every classified event can be examined with video evidence, contextual detail, and reviewer input before it is accepted into reporting. The review workspace turns VLM output into an operational process. Reviewers can inspect the event clip, understand why the interaction was classified in a certain way, compare it with location context, add annotations, and confirm the final outcome. This ensures that contextual metrics remain measurable, explainable, and aligned with real store activity.
Detailed Event Review
Incident Validation Workflow
Detailed Event Review
Detailed Event Review
This workspace is designed for close inspection of an individual VLM event. The reviewer can examine the video evidence, check the timestamp, engagement level, description, confidence, and camera source, then compare the event against the store layout. Annotation tools allow important movements, products, or interaction points to be marked directly on the evidence. Reviewers can add remarks, assign a category, and confirm the final status before saving the result.
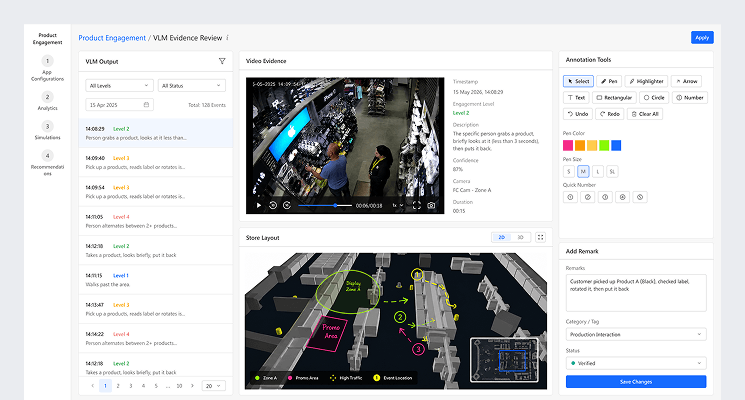
Incident Validation Workflow
Incident Validation Workflow
This view is designed for operational review at scale. Engagement incidents are presented in a structured queue, allowing teams to move quickly between events while keeping full visibility of the evidence. The workspace combines the event clip, VLM summary, evidence confidence, engagement level, product details, reviewer assignment, and approval controls. This allows the organisation to validate, escalate, or approve incidents in a disciplined workflow before the results are used in dashboards or performance analysis.
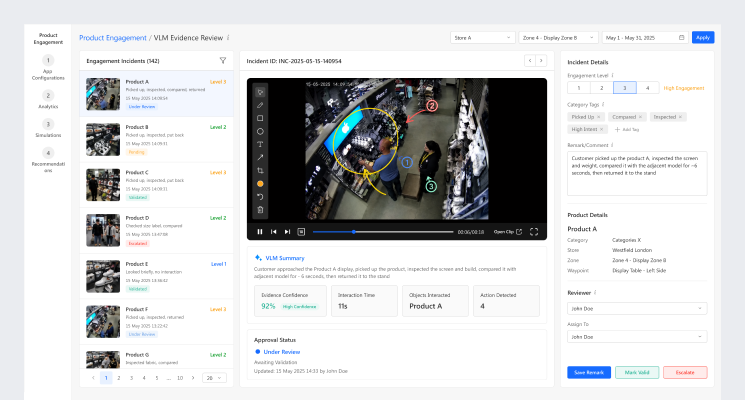
Controlled by Design
The system operates within predefined zones, triggers, questions, and categories. It focuses on the behaviours that the retailer has chosen to measure, such as engagement, service interaction, or operational adherence. Outputs are structured as categories and metrics, not unrestricted video descriptions.
Defined Scope
Analysis is limited to selected zones, event types, and operating conditions.
Defined Questions
The system answers preset business questions, such as whether product engagement or staff interaction occurred.
Defined Outputs
Results are returned as structured categories, scores, and metrics for reporting and validation.
Edge Understanding
VLM interpretation can run at the edge, close to the camera and store environment. This allows relevant events to be classified locally before structured results are sent to the platform. The focus remains on metrics, categories, and validation outputs rather than transferring unnecessary video data.
Retail Applications
VLM supports practical retail use cases where movement data alone does not provide enough context.Across store environments, VLM helps classify important moments in the customer journey and store operation. These outputs can support merchandising, service quality, checkout analysis, staff coaching, and operational compliance.

Shelf Engagement
Measure how customers interact with products, from brief attention and browsing to active evaluation and product handling.

Staff Interaction
Identify service moments such as greetings, assistance, consultation, and completed customer interactions.

Checkout Completion
Track key service stages from queue arrival through transaction, handover, and service completion.

Operational Adherence
Measure operational activities such as restocking, cleaning, merchandise handling, and task execution.

Conversion Journey
Connect engagement, service interaction, and checkout activity to understand where conversion opportunities emerge or decline.